
文章摘要
本文介绍了数据库性能优化的实践经验,包括调整联合索引字段顺序、添加多线程支持、将单条插入改为批量插入,以及使用自定义ID生成器替代IdUtil提升性能,最终使查询耗时从78秒降至2秒。
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准
https://blog.zysicyj.top
解析数据
更新索引
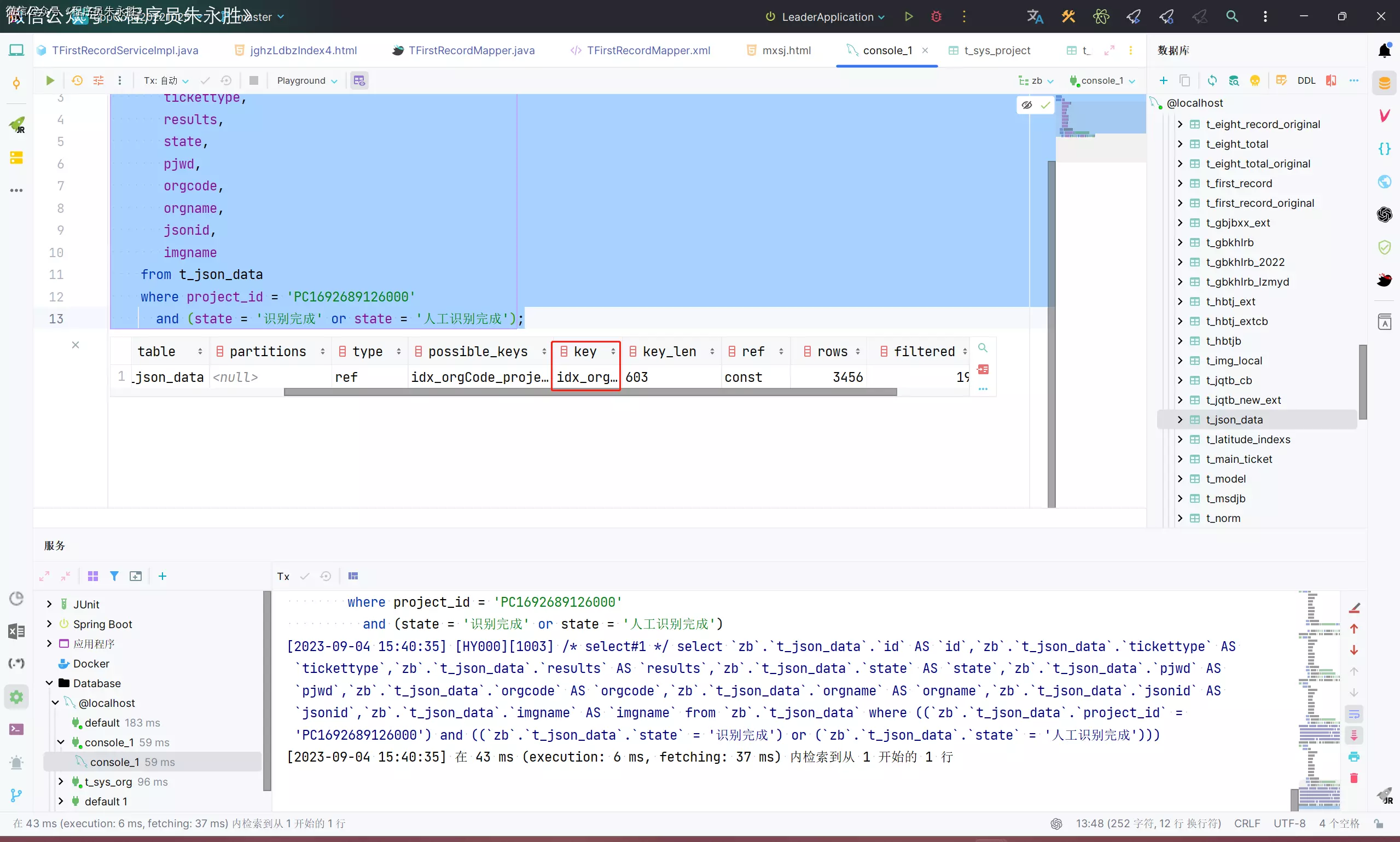
drop index idx_orgCode_projectId on t_json_data;
create index idx_orgCode_projectId
on t_json_data (project_id, orgcode)
comment '单位项目联合索引';
可以看到,更新顺序后在全量查询的时候走了索引,未更新前并没有走索引。
添加多线程支持
优化了这里性能在本地是有显著提升的,优化前差不多是78秒,优化完之后2秒多的样子。
但是这里遇到一个问题,只有idea启动的才快,使用java -jar手动启动提升,但是并没有那么惊艳。
那么这里打算继续优化
单表插入改为批量插入
原逻辑是单表查询的,这里改成批量添加比较复杂,改动就比较大了,改动中ing。。。。
汇总数据
这里主要有两个大坑
- 大量的单行插入,改为批插
- 使用IdUtil生成随机id,性能真拉跨,总共耗时2秒多,解决方法是手写了一个ID生成类
package com.nari.common.utils;
import lombok.Getter;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class IdUtilV2 {
@Getter
private static volatile IdUtilV2 instance;
static {
instance = new IdUtilV2();
// id = Long.valueOf(String.valueOf(System.nanoTime()).substring(4));
id = System.nanoTime();
}
private static Long id;
private AtomicInteger ids = new AtomicInteger(1);
private IdUtilV2() {
}
public String getIdStr() {
return cn.hutool.core.util.IdUtil.fastSimpleUUID();
}
public Long getId() {
Long value = Long.valueOf(id + "" + (ids.incrementAndGet()));
log.warn("id--:{}", value);
return value;
}
}
导出性能优化
这里单独写了一篇文章总结:http://blog.zysicyj.top/3ffdfec

本文是原创文章,采用 CC BY-NC-SA 4.0 协议,完整转载请注明来自 小朱


评论
隐私政策
0/500
滚动到此处加载评论...