并发容器之 ConcurrentHashMap(三)
并发容器之 ConcurrentHashMap(三)
程序员朱永胜参考资料:JAVA 并发实现原理:JDK 源码剖析
作者:余春龙
接下来我们说说 JDK8 中的实现。JDK8 中比较重要的两个变化如下:
- 取消了分段锁,所有数据存放在一个大的 HashMap 中
- 引入了红黑树
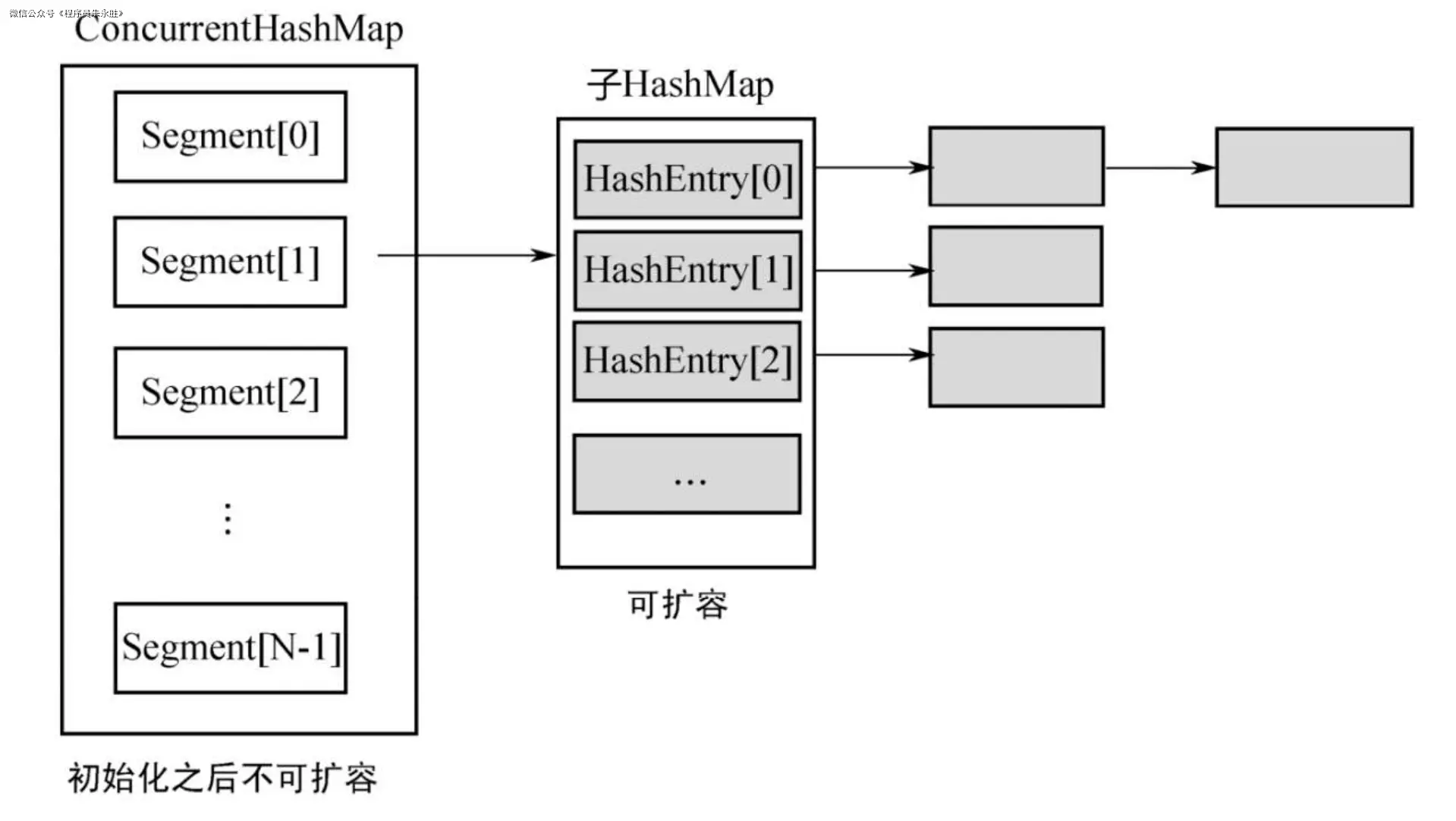
这里我们再回顾一下 JDK7 的实现原理图,对比 JDK8 实现原理
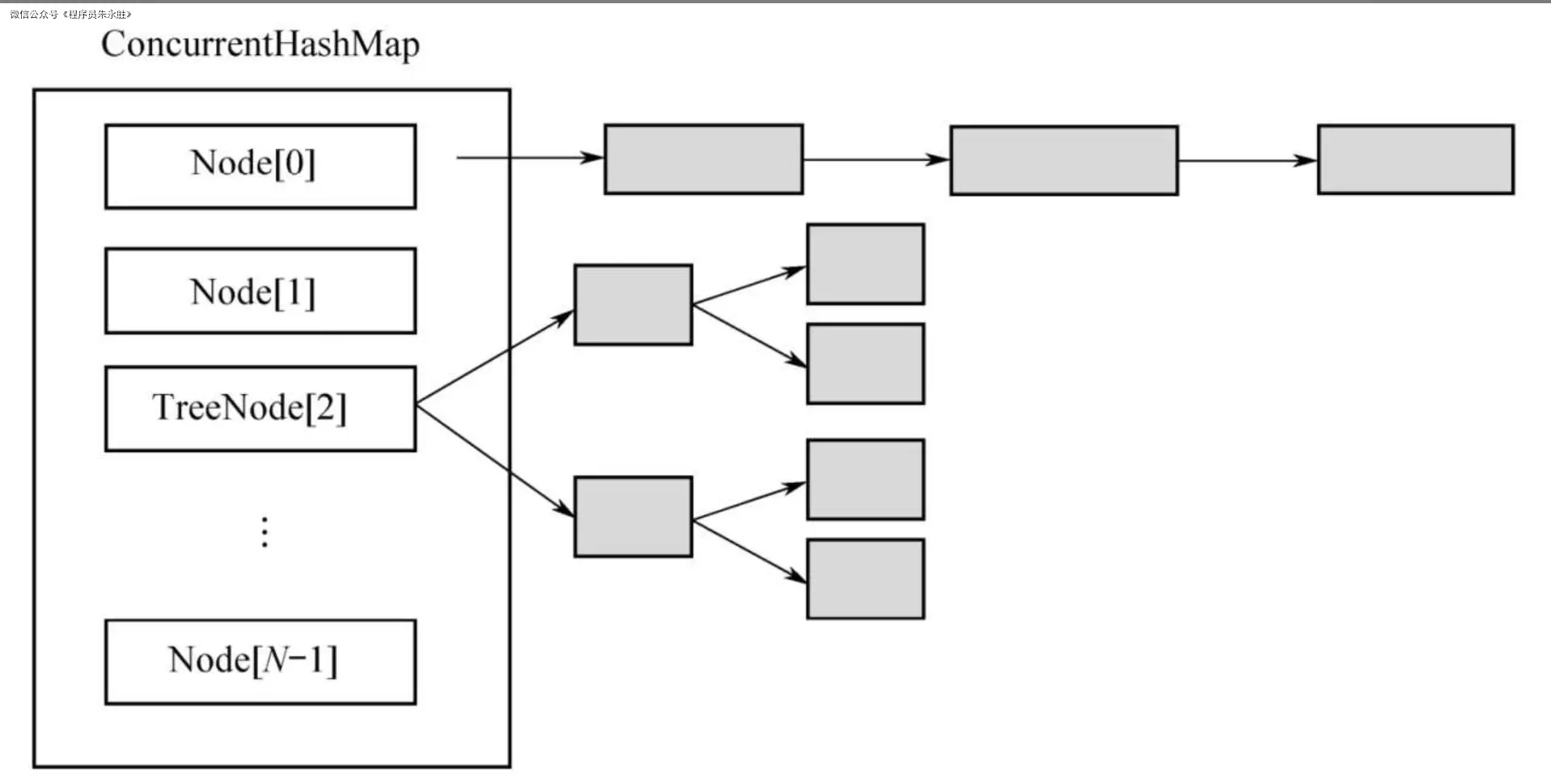
如果头节点是 Node 类型,则尾随它的就是一个普通的链表;如果头节点是 TreeNode 类型,它的后面就是一颗红黑树,TreeNode 是 Node 的子类。
红黑树
在 JDK 8 中,HashMap 的实现做了一些优化,其中之一是引入了链表和红黑树之间的相互转换规则。这一改变主要是为了提升在哈希冲突高的情况下的性能。在 JDK 7 及以前,HashMap 的桶(bucket)中存储的是链表,这在哈希冲突较多时会导致性能退化为 O(n)。JDK 8 通过在适当的条件下将链表转换为红黑树来提升性能,使得最坏情况下的时间复杂度从 O(n) 降低到 O(log n)。
在 JDK 7 中的分段锁,有三个好处:
- 减少 Hash 冲突,避免一个槽里有太多元素。
- 提高读和写的并发度。段与段之间相互独立。
- 提供扩容的并发度。扩容的时候,不是整个 ConcurrentHashMap 一起扩容,而是每个 Segment 独立扩容。
针对这三个好处,我们来看一下在 JDK 8 中相应的处理方式: - 使用红黑树,当一个槽里有很多元素时,其查询和更新速度会比链表快很多,Hash 冲突的问题由此得到较好的解决。
- 加锁的粒度,并非整个 ConcurrentHashMap,而是对每个头节点分别加锁,即并发度,就是 Node 数组的长度,初始长度为 16,和在 JDK 7 中初始 Segment 的个数相同。
- 并发扩容,这是难度最大的。在 JDK 7 中,一旦 Segment 的个数在初始化的时候确立,不能再更改,并发度被固定。之后只是在每个 Segment 内部扩容,这意味着每个 Segment 独立扩容,互不影响,不存在并发扩容的问题。但在 JDK 8 中,相当于只有 1 个 Segment,当一个线程要扩容 Node 数组的时候,其他线程还要读写,因此处理过程很复杂,后面会详细分析.
由上述对比可以总结出来:JDK 8 的实现一方面降低了 Hash 冲突,另一方面也提升了并发度。
以下是链表和红黑树之间相互转换的规则:
链表转为红黑树的条件
链表长度达到阈值 :
当一个桶中的链表长度超过阈值(默认值为 8)时,会触发链表向红黑树的转换。这个阈值在HashMap的源码中由TREEIFY_THRESHOLD常量定义,默认值为 8。HashMap 的大小超过最小树化容量 :
当HashMap的容量(size)超过最小树化容量(默认值为 64)时,链表才会转换为红黑树。这个阈值在HashMap的源码中由MIN_TREEIFY_CAPACITY常量定义,默认值为 64。
如果 HashMap 的容量没有超过 MIN_TREEIFY_CAPACITY,即使桶中的链表长度超过了 TREEIFY_THRESHOLD,HashMap 也只会进行扩容(resize)而不会进行树化。
红黑树转为链表的条件
当红黑树中的节点数量减少到一定阈值(默认值为 6)时,会将红黑树转换回链表。这个阈值在 HashMap 的源码中由 UNTREEIFY_THRESHOLD 常量定义,默认值为 6。这是为了避免当节点较少时维护红黑树的额外开销。
源码分析
下面是 HashMap 源码中与链表和红黑树转换相关的部分代码:
1 | // 转换链表为红黑树的阈值 |
在上面的代码中,treeifyBin 方法负责将链表转换为红黑树,而 untreeify 方法则负责将红黑树转换为链表。TREEIFY_THRESHOLD 和 UNTREEIFY_THRESHOLD 分别控制了链表和红黑树之间的转换阈值,而 MIN_TREEIFY_CAPACITY 则确保只有在 HashMap 的容量足够大时才进行树化操作。
通过这些规则和优化,JDK 8 中的 HashMap 能够在面对大量哈希冲突时保持较高的性能,从而提升整体效率。
下面我们详细的一步步分析
构造函数分析
1 | // 指定初始容量和负载因子的构造函数 |
结论:
- 设定的阈值并不是真实的阈值,他会自动计算最接近你给的容量的 2 的幂次为容量
- 所有的容量都是 2 的幂次
初始化
在上面的构造函数里只计算了数组的初始大小,并没有对数组进行初始化。当多个线程都往里面放入元素的时候,再进行初始化。这就存在一个问题:多个线程重复初始化。下面看一下是如何处理的。
1 | /** |
详细解释
变量声明:
Node<K,V>[] tab:声明桶数组。int sc:声明临时变量,用于存储sizeCtl的值。
循环检查和初始化:
while ((tab = table) == null || tab.length == 0):检查桶数组是否为空或长度为 0。如果是,则进入循环。if ((sc = sizeCtl) < 0):将sizeCtl的值赋给sc并检查是否小于 0。如果sizeCtl小于 0,表示当前有其他线程正在初始化桶数组,调用Thread.yield()让出 CPU 时间片,避免自旋等待。else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)):尝试将sizeCtl的值从sc设置为 -1,表示当前线程正在初始化。如果成功,进入try块。
实际初始化逻辑:
if ((tab = table) == null || tab.length == 0):再次检查桶数组是否为空或长度为 0。int n = (sc > 0) ? sc : DEFAULT_CAPACITY:如果sizeCtl大于 0,则使用sizeCtl的值作为初始容量;否则,使用默认容量DEFAULT_CAPACITY。@SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]:创建新的桶数组nt。table = tab = nt:将新创建的桶数组赋值给table和tab。sc = n - (n >>> 2):计算新的sizeCtl值,即容量的 0.75 倍。
恢复
sizeCtl值并退出循环:finally { sizeCtl = sc; }:在finally块中将sizeCtl恢复为新计算的值。break:退出循环。
返回初始化后的桶数组:
return tab:返回初始化后的桶数组。
通过上面的代码可以看到,多个线程的竞争是通过对 sizeCtl 进行 CAS 操作实现的。如果某个线程成功地把 sizeCtl 设置为 -1,它就拥有了初始化的权利,进入初始化的代码模块,等到初始化完成,再把 sizeCtl 设置回去;其他线程则一直执行 while 循环,自旋等待,直到数组不为 null,即当初始化结束时,退出整个函数。因为初始化的工作量很小,所以此处选择的策略是让其他线程一直等待,而没有帮助其初始化。\
Put 实现分析
好的,下面是详细注释后的 put 和 putVal 方法的代码:
put 方法
1 | /** |
putVal 方法
1 | /** |
详细解释
put方法:- 调用
putVal方法来实现put操作。
- 调用
putVal方法:- 参数检查:
- 检查键和值是否为空,如果为空,则抛出
NullPointerException。
- 检查键和值是否为空,如果为空,则抛出
- 哈希计算:
- 计算键的哈希值。
- 循环处理桶数组:
- 进入循环,处理桶数组。
- 如果桶数组为空或长度为 0,则初始化桶数组。
- 计算索引,如果对应位置为空,则使用 CAS 操作插入新节点。
- 如果哈希值为
MOVED,表示正在扩容,协助迁移。 - 如果桶中第一个节点的哈希值大于等于 0,表示是链表,遍历链表,查找或插入节点。
- 如果是树节点,调用
putTreeVal方法处理树节点。
- 同步处理:
- 锁定桶中的第一个节点,防止并发修改。
- 树化处理:
- 判断链表长度是否超过阈值,超过则树化。
- 更新计数:
- 调用
addCount方法更新计数,并进行必要的扩容。
- 调用
- 参数检查:
这段代码的主要功能是将键值对插入到 ConcurrentHashMap 中,并在必要时进行扩容和树化处理,以提高性能和存储效率。
上面的 for 循环有 4 个大的分支:
第 1 个分支,是整个数组的初始化,前面已讲;
第 2 个分支,是所在的槽为空,说明该元素是该槽的第一个元素,直接新建一个头节点,然后返回;
第 3 个分支,说明该槽正在进行扩容,帮助其扩容;
第 4 个分支,就是把元素放入槽内。槽内可能是一个链表,也可能是一棵红黑树,通过头节点的类型可以判断是哪一种。第 4 个分支是包裹在 synchronized (f)里面的,f 对应的数组下标位置的头节点,意味着每个数组元素有一把锁,并发度等于数组的长度。
上面的 binCount 表示链表的元素个数,当这个数目超过 TREEIFY_THRESHOLD=8 时,把链表转换成红黑树,也就是 treeifyBin(tab,i)函数。但在这个函数内部,不一定需要进行红黑树转换,可能只做扩容操作,所以接下来从扩容讲起。











