MySQL 高可用九种方案
MySQL 高可用九种方案
程序员朱永胜有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步, 认准
https://blog.zysicyj.top
先总结下各方案硬性要求
| 选型 | 端口需求 | SSH 通信 | 最低节点数 | 硬件要求 |
|---|---|---|---|---|
| MMM | 3306 | 不需要 | 2 | 与普通 MySQL 实例相同 |
| MHA | 3306 | 需要 | 2 | 与普通 MySQL 实例相同 |
| MGR | 3306, 33061 | 不需要 | 3 | 与普通 MySQL 实例相同 |
| MySQL Cluster | 1186, 11860, 3306 | 需要 | 3 数据节点 + 2 管理节点 | 高内存、高存储、高速网络 |
| Galera Cluster | 4567, 4568, 4444 | 需要 | 3 | 高内存、高存储、高速网络 |
| PXC (Percona XtraDB Cluster) | 3306, 4567, 4568, 4444 | 需要 | 3 | 高内存、高存储、高速网络 |
MMM 方案(单主)
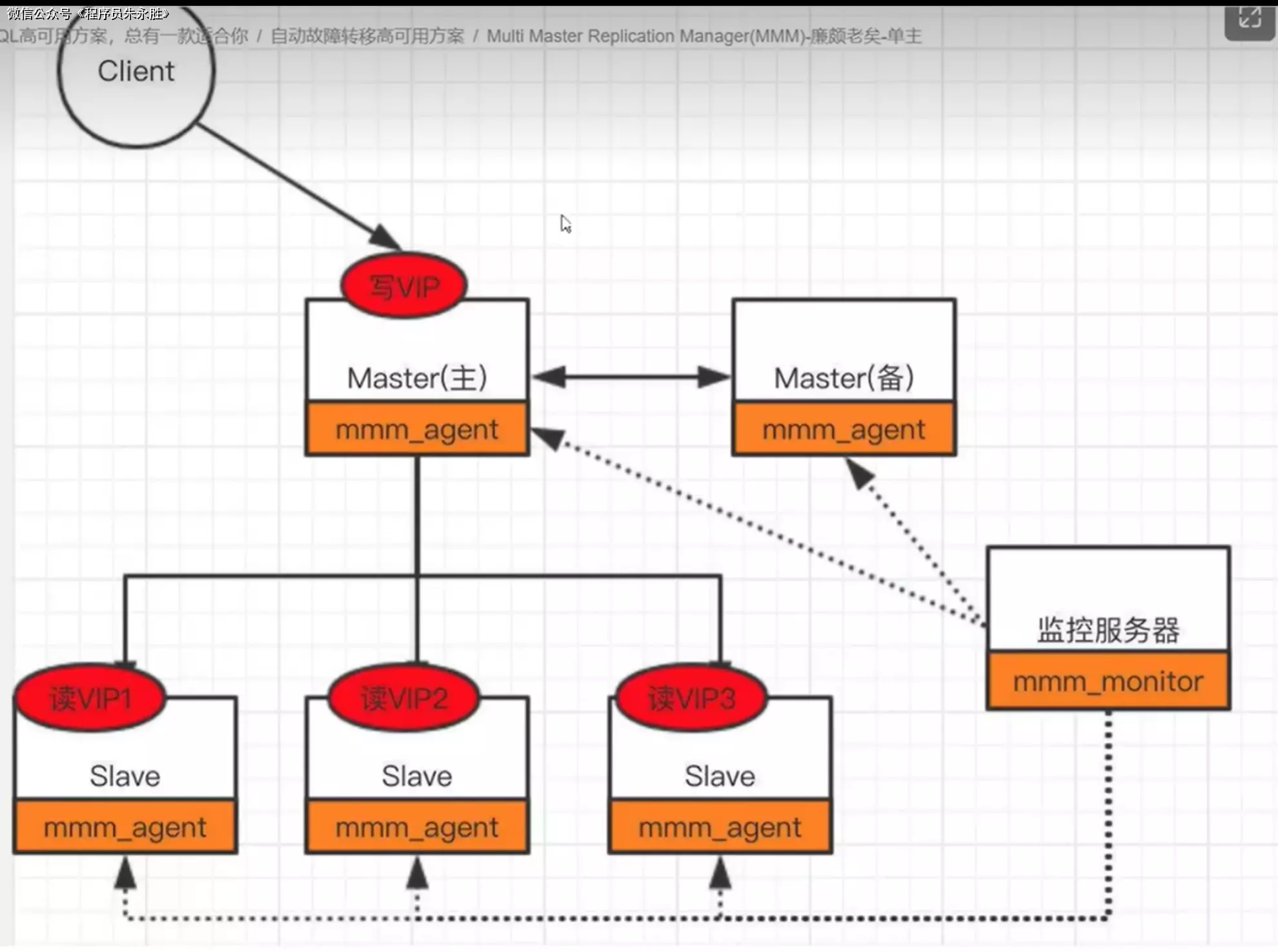
MySQL 高可用方案之 MMM(Multi-Master Replication Manager)是一种常用的解决方案,用于实现 MySQL 数据库的高可用性和负载均衡。
MMM 基于 MySQL 的复制机制,通过在多个 MySQL 实例之间进行主从复制,实现了数据的同步和备份。它的主要特点是可以实现多主复制,即多个 MySQL 实例可以同时作为主节点接收写操作,并将这些写操作同步到其他从节点上。
MMM 的工作原理如下:
- MMM 通过监控 MySQL 实例的状态来实现故障检测和自动故障转移。当一个主节点发生故障时,MMM 会自动将其中一个从节点提升为新的主节点,确保数据库的可用性。
- MMM 还可以根据负载情况自动进行负载均衡。它可以根据每个节点的负载情况,将读操作分发到不同的节点上,从而提高系统的整体性能。
- MMM 还提供了一些管理工具,可以方便地进行节点的添加、删除和配置修改等操作。
使用 MMM 可以有效地提高 MySQL 数据库的可用性和性能。然而,需要注意的是,MMM 并不能解决所有的高可用问题,例如 ** 网络分区和数据一致性
** 等问题。在实际应用中,还需要结合其他技术和方案,如数据库集群、数据复制和数据备份等,来构建更完善的高可用架构。
MMM 作为 MySQL 高可用方案,具有以下优点和缺点:
优点:
- 高可用性:MMM 通过自动故障检测和故障转移机制,可以快速将一个从节点提升为新的主节点,从而实现数据库的高可用性,减少系统的停机时间。
- 负载均衡:MMM 可以根据节点的负载情况,将读操作分发到不同的节点上,从而实现负载均衡,提高系统的整体性能。
- 简单易用:MMM 提供了一些管理工具,可以方便地进行节点的添加、删除和配置修改等操作,使得系统的管理和维护变得简单易用。
缺点:
- 数据一致性:由于 MMM 采用的是异步复制机制,主节点和从节点之间存在一定的延迟,可能导致数据的不一致。在某些场景下,可能需要额外的措施来确保数据的一致性。
- 单点故障:虽然 MMM 可以自动进行故障转移,但在故障转移过程中,可能会存在一段时间的数据库不可用。如果 MMM 本身发生故障,可能会导致整个系统的不可用。
- 配置复杂性:MMM 的配置相对复杂,需要对 MySQL 的复制机制和 MMM 的工作原理有一定的了解。在配置过程中,需要注意各个节点的配置一致性和正确性。
http://blog.zysicyj.top/mysql_mmm
MHA 架构(单主)
架构图
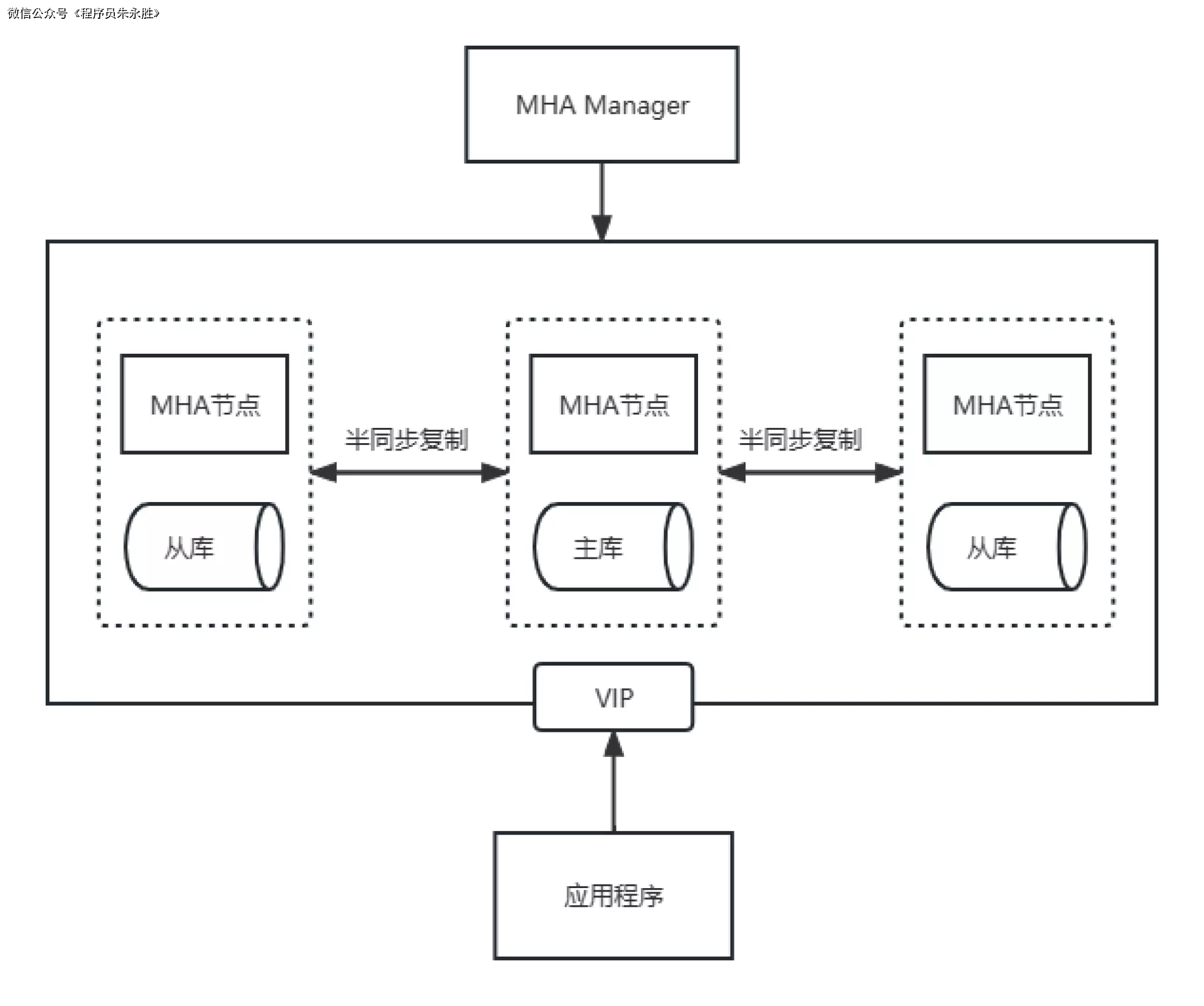
MySQL MHA(Master High Availability)是一种用于 MySQL 数据库的高可用性架构。它的设计目标是确保在主数据库发生故障时,能够快速自动地将备库(Slave)提升为新的主库,以保证系统的连续性和可用性。
MHA 架构由以下几个核心组件组成:
- Manager 节点:Manager 节点是 MHA 的核心组件,负责监控主库的状态并自动执行故障切换操作。它通过与 MySQL 主库和备库建立 SSH 连接,实时监测主库的状态,并在主库发生故障时触发自动故障切换。
- Master 节点:Master 节点是 MySQL 数据库的主库,负责处理所有的写操作和读操作。MHA 会通过与 Master 节点建立 SSH 连接,实时监测主库的状态。
- Slave 节点:Slave 节点是 MySQL 数据库的备库,负责复制主库的数据。MHA 会通过与 Slave 节点建立 SSH 连接,实时监测备库的状态。
MHA 的工作流程如下:
- Manager 节点通过 SSH 连接与 Master 节点和 Slave 节点进行通信,实时监测它们的状态。
- 当 Manager 节点检测到 Master 节点发生故障时,它会自动将一个备库提升为新的主库。
- 在故障切换期间,Manager 节点会自动更新应用程序的配置文件,将新的主库信息通知给应用程序。
- 一旦新的主库上线,Manager 节点会自动将其他备库重新配置为新的主库的从库,并开始复制数据。
MHA 架构的优点包括:
- 自动故障切换:MHA 能够自动检测主库的故障,并快速将备库提升为新的主库,减少了手动干预的需要,提高了系统的可用性。
- 实时监测:MHA 通过与 Master 节点和 Slave 节点建立 SSH 连接,实时监测它们的状态,能够及时发现故障并采取相应的措施。
- 简化配置:MHA 提供了简单易用的配置文件,可以轻松地配置主库和备库的信息,减少了配置的复杂性。
- 高可扩展性:MHA 支持多个备库,可以根据需求灵活地扩展系统的容量和性能。
MHA 架构虽然有很多优点,但也存在一些潜在的缺点:
- 配置复杂性:尽管 MHA 提供了简化的配置文件,但对于不熟悉 MHA 的用户来说,配置仍然可能是一项复杂的任务。特别是在涉及多个主库和备库的复杂环境中,配置可能变得更加困难。
- 依赖 SSH 连接:MHA 使用 SSH 连接与主库和备库进行通信和监控。这意味着在配置和使用 MHA 时,必须确保 SSH 连接的可用性和稳定性。如果 SSH 连接出现问题,可能会导致 MHA 无法正常工作。
- 故障切换过程中的数据同步延迟:在故障切换期间,MHA 需要将备库提升为新的主库,并重新配置其他备库作为新的从库。这个过程可能需要一些时间,导致在切换期间存在一定的数据同步延迟。这可能会对某些应用程序的数据一致性产生影响。
- 依赖 MySQL 复制功能:MHA 依赖 MySQL 的复制功能来实现数据的同步和复制。如果 MySQL 的复制功能出现问题,可能会导致 MHA 无法正常工作或数据同步不完整。
- 需要额外的硬件资源:为了实现高可用性,MHA 需要至少一个备库来作为冗余备份。这意味着需要额外的硬件资源来支持备库的运行和数据复制,增加了系统的成本和复杂性。
需要注意的是,MHA 并不是万能的解决方案,它适用于大多数的 MySQL 数据库场景,但在特定的情况下可能需要根据实际需求进行定制化的配置和调整。此外,为了确保 MHA 的正常运行,还需要进行定期的监控和维护工作,以保证系统的稳定性和可靠性。
MGR 架构(单 / 多主)
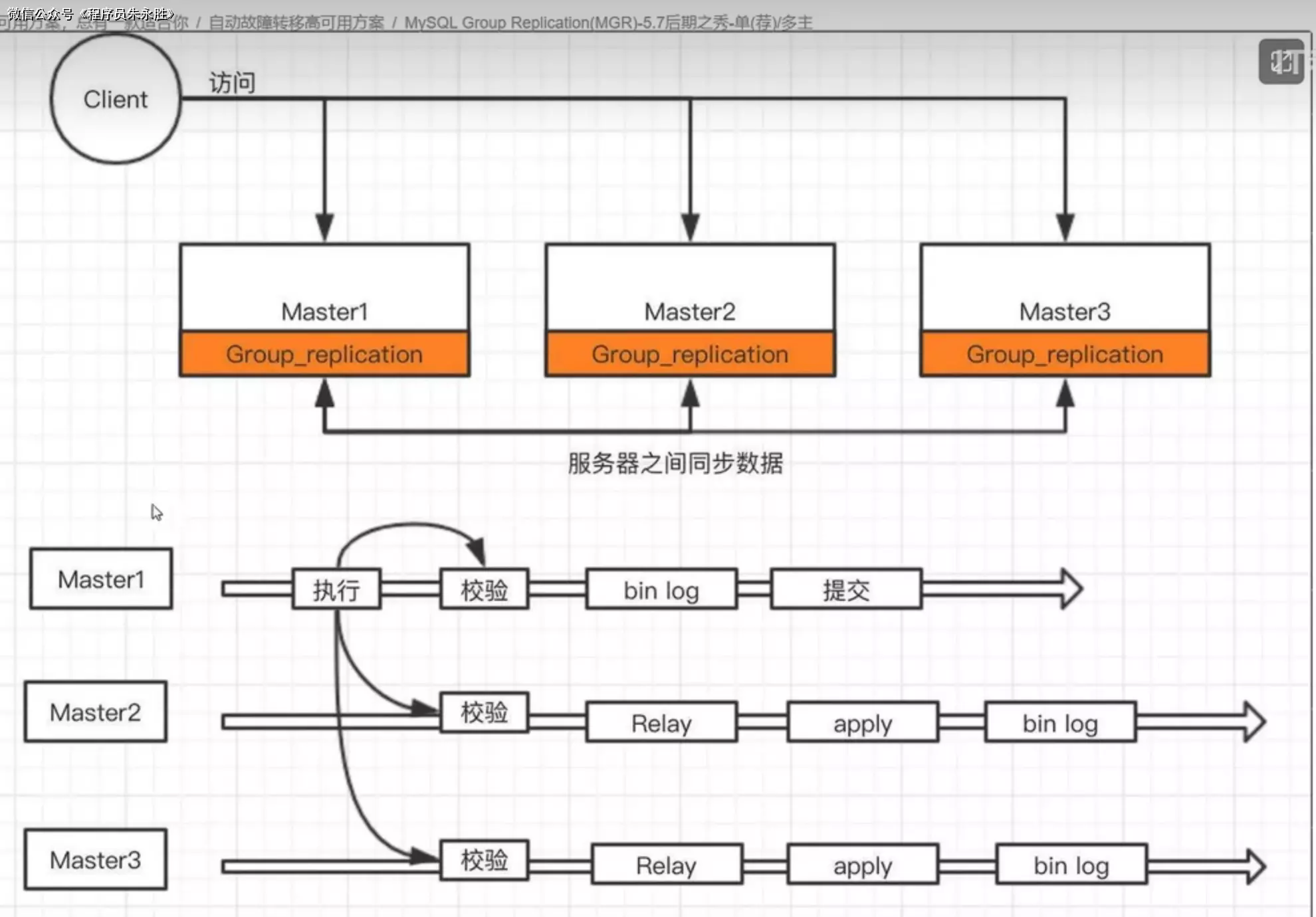
MGR(MySQL Group Replication)是 MySQL 官方提供的一种高可用性架构,用于实现 MySQL 数据库的主从复制和自动故障切换。MGR 基于 MySQL 的 InnoDB 存储引擎和 Group
Replication 插件,通过使用多主复制的方式来提供高可用性和数据一致性。
MGR 架构的核心组件包括:
- Group Replication 组件:Group Replication 是 MySQL 官方提供的插件,用于实现多主复制和自动故障切换。它基于 Paxos 协议,通过在集群中的成员之间进行通信和协调,实现数据的同步和一致性。
- Primary 节点:Primary 节点是 MGR 集群中的主节点,负责处理所有的写操作和读操作。Primary 节点接收来自应用程序的写请求,并将数据复制到其他节点(Secondary 节点)上。
- Secondary 节点:Secondary 节点是 MGR 集群中的从节点,负责复制 Primary 节点上的数据。Secondary 节点通过与 Primary 节点进行通信,接收并应用 Primary 节点上的写操作,以保持数据的一致性。
MGR 架构的工作流程如下:
初始化集群:在 MGR 架构中,首先需要选择一个节点作为初始 Primary 节点,并将其配置为 Group
Replication 组件的成员。然后,其他节点可以加入到集群中,并通过与 Primary 节点进行通信,获取数据并成为 Secondary 节点。数据同步:一旦集群初始化完成,Primary 节点开始接收来自应用程序的写请求,并将数据复制到其他节点上。Secondary 节点通过与 Primary 节点进行通信,接收并应用 Primary 节点上的写操作,以保持数据的一致性。
自动故障切换:如果 Primary 节点发生故障,Group
Replication 组件会自动选择一个 Secondary 节点作为新的 Primary 节点,并将其他节点重新配置为新的 Secondary 节点。这个过程是自动的,无需人工干预。
MGR 架构的优点包括:
- 自动故障切换:MGR 能够自动检测 Primary 节点的故障,并快速将一个 Secondary 节点提升为新的 Primary 节点,实现自动故障切换,提高了系统的可用性。
- 数据一致性:MGR 使用 Paxos 协议来保证数据的一致性。在写操作提交之前,集群中的成员会达成一致,确保数据在所有节点上的复制是一致的。
- 简化配置和管理:MGR 提供了简单易用的配置选项和管理工具,使得集群的配置和管理变得更加简单和方便。
- 高可扩展性:MGR 支持多主复制,可以根据需求灵活地扩展系统的容量和性能。
需要注意的是,MGR 架构也有一些限制和注意事项:
- 网络稳定性:MGR 对网络的稳定性要求较高,因为节点之间需要进行频繁的通信和数据同步。如果网络不稳定,可能会导致数据同步延迟或节点之间的通信故障。
- 数据冲突:由于 MGR 支持多主复制,如果应用程序在不同的节点上同时进行写操作,可能会导致数据冲突和一致性问题。因此,需要在应用程序层面进行合理的设计和处理。
- 配置复杂性:尽管 MGR 提供了简化的配置选项和管理工具,但对于不熟悉 MGR 的用户来说,配置仍然可能是一项复杂的任务。特别是在涉及多个节点和复杂环境中,配置可能变得更加困难。
在使用 MGR 之前,建议进行充分的测试和评估,以确保它能够满足系统的可用性和性能要求,并根据具体的应用场景和需求进行适当的配置和调整。
Mysql cluster(官方亲儿子)(多主)
官方 PDF 文档:
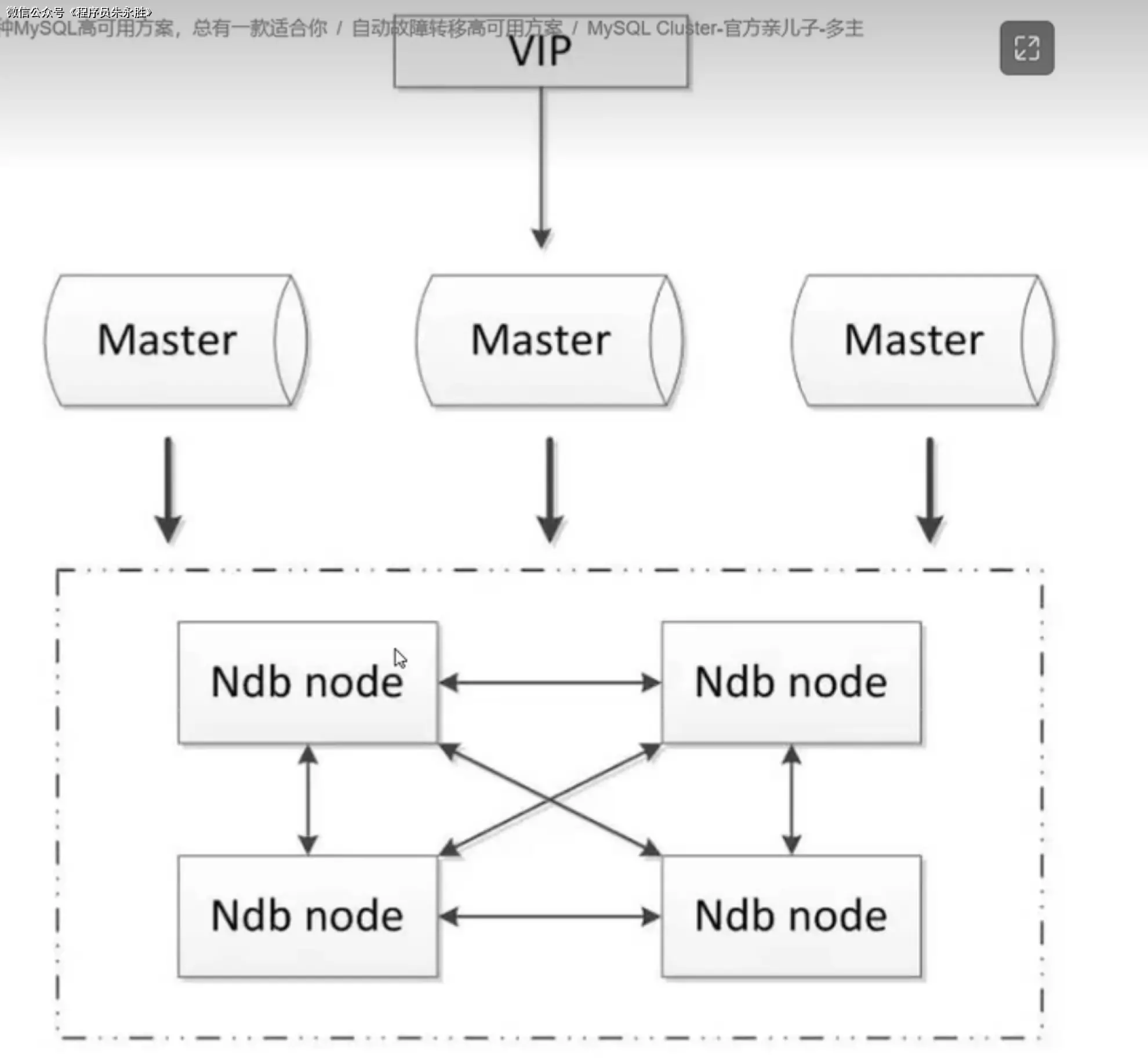
MySQL Cluster 是 MySQL 官方提供的一种分布式数据库解决方案,旨在提供高可用性、可扩展性和实时性能。它基于 NDB(Network
DataBase)存储引擎,使用多台服务器组成一个集群,提供数据的分片和复制,以实现高可用性和负载均衡。
MySQL Cluster 架构的核心组件包括:
- Management 节点:Management 节点是 MySQL Cluster 的控制节点,负责集群的管理和配置。它负责监控集群中的各个节点,并协调数据的分片和复制。
- Data 节点:Data 节点是 MySQL Cluster 的存储节点,负责存储和处理数据。每个 Data 节点都运行 NDB 存储引擎,数据被分片存储在不同的 Data 节点上,以实现数据的分布和负载均衡。
- SQL 节点:SQL 节点是 MySQL Cluster 的查询节点,负责处理应用程序的查询请求。SQL 节点接收来自应用程序的 SQL 查询,并将查询分发到适当的 Data 节点上进行处理。
MySQL Cluster 架构的工作流程如下:
集群初始化:在 MySQL Cluster 中,首先需要配置和启动 Management 节点,然后配置和启动 Data 节点和 SQL 节点。Management 节点负责监控和管理集群中的各个节点。
数据分片和复制:一旦集群初始化完成,Management 节点会根据配置的规则将数据分片存储在不同的 Data 节点上。数据的复制和同步由 MySQL
Cluster 自动处理,以保证数据的一致性和可用性。查询处理:当应用程序发送查询请求时,SQL 节点接收并解析查询,并将查询分发到适当的 Data 节点上进行处理。Data 节点返回查询结果给 SQL 节点,然后 SQL 节点将结果返回给应用程序。
MySQL Cluster 架构的优点包括:
- 高可用性:MySQL Cluster 通过数据的分片和复制,以及自动故障检测和恢复机制,实现了高可用性。即使某个节点发生故障,集群仍然可以继续提供服务。
- 可扩展性:MySQL Cluster 支持水平扩展,可以通过增加 Data 节点来扩展存储容量和处理能力。同时,由于数据的分片和负载均衡,可以实现更好的性能和吞吐量。
- 实时性能:MySQL Cluster 的设计目标之一是提供实时性能。通过将数据存储在内存中,并使用并行处理和分布式计算,可以实现较低的延迟和更高的吞吐量。
- 数据一致性:MySQL Cluster 使用多副本复制和同步机制,以保证数据的一致性。即使在节点故障或网络分区的情况下,数据仍然可以保持一致。
需要注意的是,MySQL Cluster 也有一些限制和注意事项:
配置复杂性:MySQL Cluster 的配置相对复杂,需要考虑数据分片、复制和负载均衡等因素。对于不熟悉 MySQL
Cluster 的用户来说,配置可能是一项具有挑战性的任务。内存需求:由于 MySQL Cluster 将数据存储在内存中,因此对内存的需求较高。需要根据数据量和性能需求来配置足够的内存资源。
网络稳定性:MySQL Cluster 对网络的稳定性要求较高,因为节点之间需要进行频繁的通信和数据同步。如果网络不稳定,可能会导致数据同步延迟或节点之间的通信故障。
在使用 MySQL Cluster 之前,建议进行充分的测试和评估,以确保它能够满足系统的可用性、性能和扩展性要求,并根据具体的应用场景和需求进行适当的配置和调整。
Galera Cluster(多主)
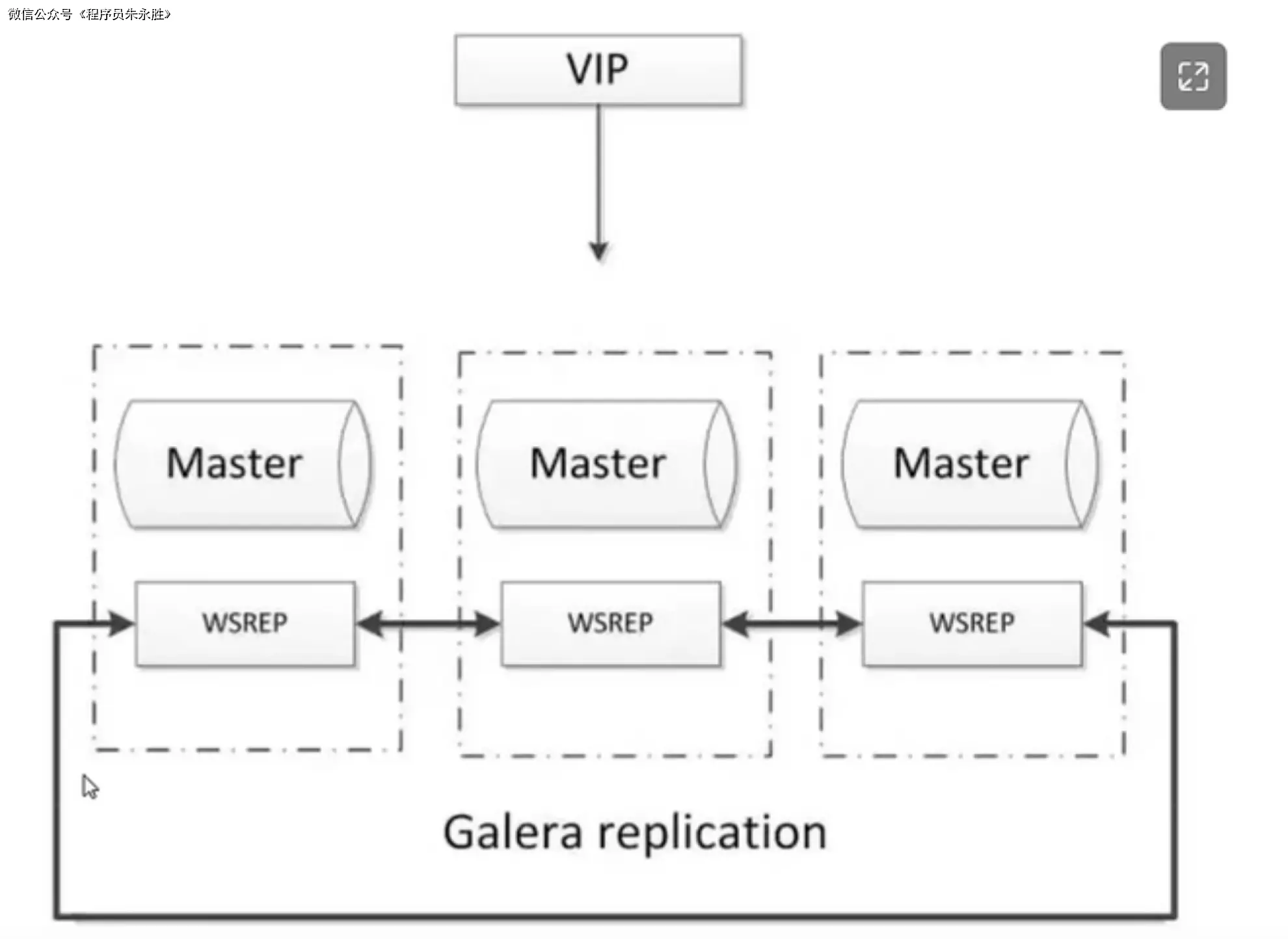
Galera Cluster 是一个基于同步多主复制的 MySQL 集群解决方案。它使用 Galera Replication 插件,通过在多个 MySQL 节点之间同步数据来实现高可用性和负载均衡。
Galera Cluster 的核心组件包括:
Galera Replication 插件:Galera Replication 是一个基于同步复制的插件,用于实现数据的多主复制和一致性。它使用了多主复制协议,确保在集群中的所有节点之间的数据同步和一致性。
Primary Component:Primary Component 是 Galera Cluster 中的主组件,负责处理所有的写操作和读操作。Primary
Component 接收来自应用程序的写请求,并将数据复制到其他节点(Secondary Component)上。Secondary Component:Secondary Component 是 Galera Cluster 中的从组件,负责复制 Primary Component 上的数据。Secondary
Component 通过与 Primary Component 进行通信,接收并应用 Primary Component 上的写操作,以保持数据的一致性。
Galera Cluster 的工作流程如下:
初始化集群:在 Galera Cluster 中,首先需要配置和启动一个节点作为初始 Primary Component,并将其配置为 Galera
Replication 插件的成员。然后,其他节点可以加入到集群中,并通过与 Primary Component 进行通信,获取数据并成为 Secondary
Component。数据同步和复制:一旦集群初始化完成,Primary Component 开始接收来自应用程序的写请求,并将数据复制到其他节点上。Secondary
Component 通过与 Primary Component 进行通信,接收并应用 Primary Component 上的写操作,以保持数据的一致性。自动故障切换:如果 Primary Component 发生故障,Galera Cluster 会自动选择一个 Secondary Component 作为新的 Primary
Component,并将其他节点重新配置为新的 Secondary Component。这个过程是自动的,无需人工干预。
Galera Cluster 的优点包括:
- 高可用性:Galera Cluster 通过数据的多主复制和自动故障切换,实现了高可用性。即使某个节点发生故障,集群仍然可以继续提供服务。
- 数据一致性:Galera Cluster 使用多主复制协议,确保在集群中的所有节点之间的数据同步和一致性。在写操作提交之前,集群中的成员会达成一致,确保数据在所有节点上的复制是一致的。
- 简化配置和管理:Galera Cluster 提供了简单易用的配置选项和管理工具,使得集群的配置和管理变得更加简单和方便。
- 可扩展性:Galera Cluster 支持水平扩展,可以通过增加节点来扩展存储容量和处理能力。同时,由于数据的多主复制和负载均衡,可以实现更好的性能和吞吐量。
需要注意的是,Galera Cluster 也有一些限制和注意事项:
- 网络稳定性:Galera Cluster 对网络的稳定性要求较高,因为节点之间需要进行频繁的通信和数据同步。如果网络不稳定,可能会导致数据同步延迟或节点之间的通信故障。
- 写冲突:由于 Galera Cluster 支持多主复制,如果应用程序在不同的节点上同时进行写操作,可能会导致写冲突和一致性问题。因此,需要在应用程序层面进行合理的设计和处理。
- 配置复杂性:尽管 Galera Cluster 提供了简化的配置选项和管理工具,但对于不熟悉 Galera Cluster 的用户来说,配置可能是一项具有挑战性的任务。
在使用 Galera Cluster 之前,建议进行充分的测试和评估,以确保它能够满足系统的可用性、性能和扩展性要求,并根据具体的应用场景和需求进行适当的配置和调整。
PXC 架构(多主)
PXC(Percona XtraDB Cluster)是一个基于 Galera Cluster 的高可用性和高性能的 MySQL 集群解决方案。它是由 Percona 开发的,建立在 Galera
Replication 插件之上,提供了多主复制和数据同步的功能。
PXC 架构的核心组件包括:
Galera Replication 插件:PXC 使用 Galera Replication 插件来实现数据的多主复制和一致性。该插件基于同步复制的原理,确保在集群中的所有节点之间的数据同步和一致性。
Primary Component:Primary Component 是 PXC 集群中的主组件,负责处理所有的写操作和读操作。Primary
Component 接收来自应用程序的写请求,并将数据复制到其他节点(Secondary Component)上。Secondary Component:Secondary Component 是 PXC 集群中的从组件,负责复制 Primary Component 上的数据。Secondary
Component 通过与 Primary Component 进行通信,接收并应用 Primary Component 上的写操作,以保持数据的一致性。
PXC 架构的工作流程如下:
初始化集群:在 PXC 中,首先需要配置和启动一个节点作为初始 Primary Component,并将其配置为 Galera
Replication 插件的成员。然后,其他节点可以加入到集群中,并通过与 Primary Component 进行通信,获取数据并成为 Secondary
Component。数据同步和复制:一旦集群初始化完成,Primary Component 开始接收来自应用程序的写请求,并将数据复制到其他节点上。Secondary
Component 通过与 Primary Component 进行通信,接收并应用 Primary Component 上的写操作,以保持数据的一致性。自动故障切换:如果 Primary Component 发生故障,PXC 会自动选择一个 Secondary Component 作为新的 Primary
Component,并将其他节点重新配置为新的 Secondary Component。这个过程是自动的,无需人工干预。
PXC 架构的优点包括:
- 高可用性:PXC 通过数据的多主复制和自动故障切换,实现了高可用性。即使某个节点发生故障,集群仍然可以继续提供服务。
- 数据一致性:PXC 使用 Galera Replication 插件,确保在集群中的所有节点之间的数据同步和一致性。在写操作提交之前,集群中的成员会达成一致,确保数据在所有节点上的复制是一致的。
- 简化配置和管理:PXC 提供了简单易用的配置选项和管理工具,使得集群的配置和管理变得更加简单和方便。
- 可扩展性:PXC 支持水平扩展,可以通过增加节点来扩展存储容量和处理能力。同时,由于数据的多主复制和负载均衡,可以实现更好的性能和吞吐量。
需要注意的是,PXC 也有一些限制和注意事项:
- 网络稳定性:PXC 对网络的稳定性要求较高,因为节点之间需要进行频繁的通信和数据同步。如果网络不稳定,可能会导致数据同步延迟或节点之间的通信故障。
- 写冲突:由于 PXC 支持多主复制,如果应用程序在不同的节点上同时进行写操作,可能会导致写冲突和一致性问题。因此,需要在应用程序层面进行合理的设计和处理。
- 配置复杂性:尽管 PXC 提供了简化的配置选项和管理工具,但对于不熟悉 PXC 的用户来说,配置可能是一项具有挑战性的任务。
在使用 PXC 之前,建议进行充分的测试和评估,以确保它能够满足系统的可用性、性能和扩展性要求,并根据具体的应用场景和需求进行适当的配置和调整。
RAID10(数据可靠性方案)(单点问题)
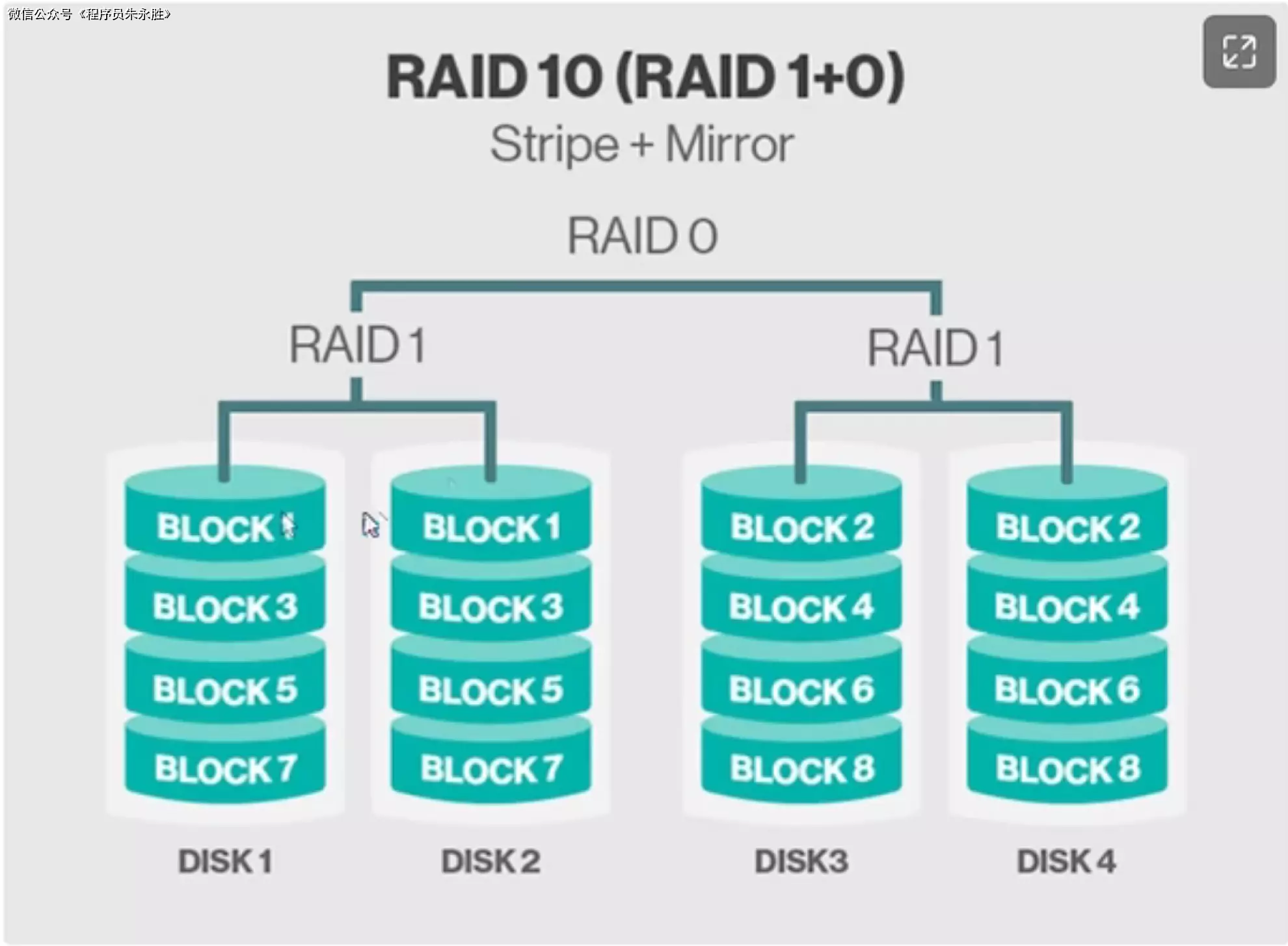
RAID10(Redundant Array of Independent Disks 10)是一种存储方案,它结合了 RAID 1(镜像)和 RAID
0(条带化)的特性。RAID10 通过将多个磁盘组合在一起,提供了数据冗余和性能增强的优势。
在 RAID10 中,磁盘被分为两组,每组至少有两个磁盘。其中一组磁盘使用镜像技术,即数据被同时写入两个磁盘,提供了数据的冗余备份。另一组磁盘使用条带化技术,即数据被分块地写入多个磁盘,提供了更好的读写性能。
RAID10 的特点和优势包括:
- 数据冗余:RAID10 通过镜像技术提供了数据的冗余备份。如果一个磁盘发生故障,数据仍然可以从镜像磁盘中恢复,保证了数据的可靠性和可用性。
- 高性能:RAID10 通过条带化技术提供了更好的读写性能。数据可以同时从多个磁盘读取或写入,提高了数据访问的速度和吞吐量。
- 故障容忍:由于 RAID10 具有数据冗余性,当一个磁盘发生故障时,系统可以继续正常运行,并且可以在更换故障磁盘后进行数据恢复,减少了系统停机时间。
- 容量利用率:RAID10 的容量利用率较低,因为数据被同时写入两个磁盘。例如,如果有 4 个 1TB 的磁盘组成 RAID10,实际可用的存储容量只有 2TB。
需要注意的是,RAID10 的缺点包括:
- 成本较高:由于 RAID10 需要使用多个磁盘进行数据镜像和条带化,所以成本较高。相比其他 RAID 级别,RAID10 需要更多的磁盘。
- 容量利用率较低:由于数据被同时写入两个磁盘,RAID10 的容量利用率较低。如果容量是一个关键因素,可能需要考虑其他 RAID 级别。
RAID10 适用于对数据冗余性和性能要求较高的应用场景,如数据库服务器、虚拟化环境和高性能计算等。在选择 RAID 级别时,需要根据具体的需求和预算来权衡各种因素。
SAN 存储网络(数据存储解决方案)(除了贵没有缺点)
SAN(Storage Area Network)是一种专门用于存储数据的高速网络架构。它将存储设备(如磁盘阵列、磁带库等)与服务器连接起来,提供高性能、高可用性和可扩展性的存储解决方案。
SAN 存储网络的特点和优势包括:
- 存储共享:SAN 允许多台服务器共享存储设备,使得数据可以在不同的服务器之间共享和访问。这样可以提高数据的灵活性和共享性,减少存储资源的浪费。
- 高性能:SAN 使用高速的网络连接(如光纤通道、以太网等),提供了高带宽和低延迟的数据传输。这使得存储设备可以提供更高的读写性能,满足对存储性能要求较高的应用场景。
- 高可用性:SAN 通过冗余和故障切换机制,提供了高可用性的存储解决方案。如果一个存储设备或连接发生故障,系统可以自动切换到备用设备或路径,保证数据的可靠性和可用性。
- 可扩展性:SAN 具有良好的可扩展性,可以根据需求灵活地扩展存储容量和性能。通过添加新的存储设备或扩展现有设备的容量,可以满足不断增长的存储需求。
- 管理简便:SAN 提供了集中管理和监控的功能,使得存储资源的配置、监控和管理变得更加简便和高效。管理员可以通过集中的管理界面对存储设备进行配置和管理,提高了管理效率。
需要注意的是,SAN 存储网络也有一些限制和注意事项:
- 成本较高:相比于其他存储解决方案,SAN 的成本较高。它需要专用的硬件设备和高速网络连接,这增加了部署和维护的成本。
- 配置复杂性:SAN 的配置和管理相对复杂,需要专业的知识和技能。对于不熟悉 SAN 的用户来说,配置和管理可能是一项具有挑战性的任务。
SAN 存储网络适用于对存储性能、可用性和扩展性要求较高的应用场景,如大型企业、数据中心、虚拟化环境等。在选择和部署 SAN 存储网络时,需要根据具体的需求和预算来权衡各种因素,并确保与服务器和应用程序的兼容性。
DRBD 方案(数据存储解决方案)(系统自带)
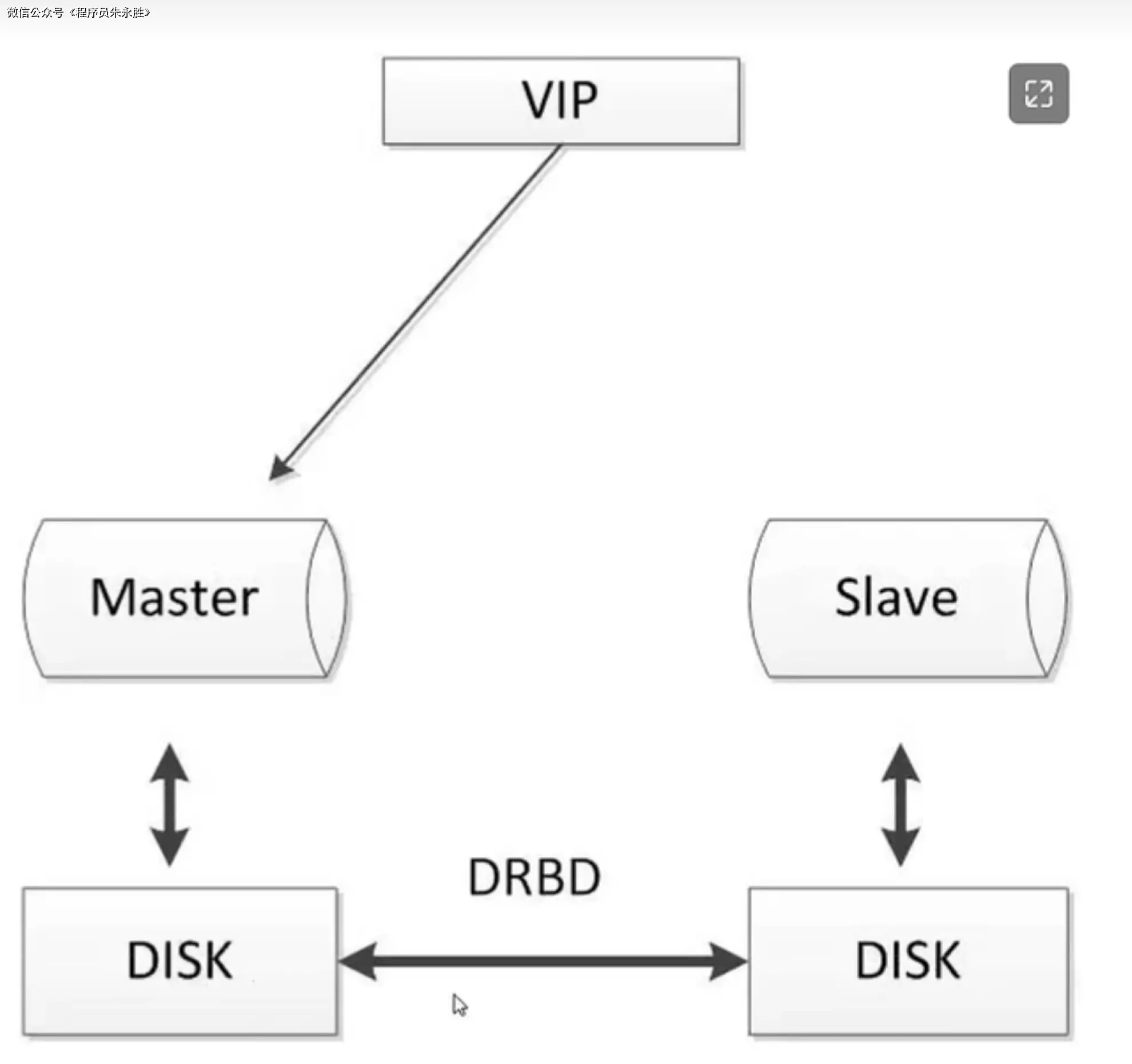
MySQL 与 DRBD 结合使用可以实现高可用性的数据库方案。通过将 MySQL 数据库的数据目录配置为 DRBD 设备,可以实现数据的实时复制和故障转移。
在 MySQL 与 DRBD 方案中,通常会有两个节点:一个主节点和一个备节点。主节点负责处理所有的读写操作,并将数据实时复制到备节点上。备节点会持续地从主节点复制数据,以保持数据的一致性。
当主节点发生故障时,备节点可以接管主节点的角色,成为新的主节点,继续提供数据库服务。这种故障转移过程是自动的,可以通过配置和管理工具(如 Pacemaker)来实现。
使用 MySQL 与 DRBD 方案可以提供数据库的冗余和故障转移能力,从而提高数据库的可靠性和可用性。当主节点发生故障时,系统可以自动切换到备节点,减少数据库服务的中断时间。
需要注意的是,配置和管理 MySQL 与 DRBD 方案需要一定的技术知识和经验。此外,对网络的稳定性和带宽要求较高,以确保数据的实时复制和同步。因此,在实施该方案之前,建议进行充分的规划和测试,以确保系统的稳定性和可靠性。











